Some while ago I wrote how we make sure that the documented and the actual architecture match using the idea of Executable Architecture Documentation. This time I want to re-visit this again, but now a little bit more as a tutorial.
An ultra-short recapitulation of the idea
arc42 is a widely used template for architecture documentation. Chapter 5 describes the Building Block View UML Package diagrams can be used to picture the building blocks. There is the current version of the arc42 template on GitHub. Out of the template in Asciidoc several other formats can be generated, but we go with Asciidoc. PlantUML is a Domain Specific Language to describe UML diagrams in textual notation and tooling to make standalone or embedded graphics out of this. jQAssistant scans Java projects into a Neo4j database and can be easily extended by plugins. Kontext E provides a Plugin for reading PlantUML package diagrams.
So the main building blocks described in the architecture documentation can be put into the same database where the actual architecture artifacts are located. Only one simple Cypher query is needed to compare the documented and actual package dependencies.
Add the PlantUML plugin to the jQAssistant configuration
First we need to add the Kontext E PlantUML plugin to jQAssistant in the build file. In the following sections I’ll give examples for Maven and Gradle
Maven
As described in the jQAssistant documentation you add another dependency to the jQA Maven plugin:
1
2
3
4
5
6
7
<dependencies>
<dependency>
<groupId>de.kontext-e.jqassistant.plugin</groupId>
<artifactId>jqassistant.plugin.plantuml</artifactId>
<version>1.1.4</version>
</dependency>
</dependencies>
Gradle
Given you have a separate configuration for jQAssistant plugins:
1
2
3
configurations {
jqaRt
}
you add the PlantUML plugin this way:
1
jqaRt("de.kontext-e.jqassistant.plugin:jqassistant.plugin.plantuml:1.1.4")
Put the PlantUML diagram into arc42 Building Block View chapter
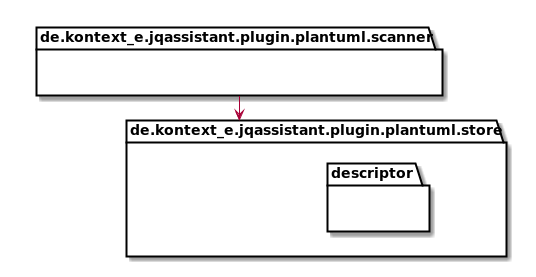
It is quite easy to put a UML diagram into an Asciidoc file. For the jQA PlantUML plugin itself it could look like this:
["plantuml","MainBuildingBlocks.png","png"]
-----
package de.kontext_e.jqassistant.plugin.plantuml.scanner {}
package de.kontext_e.jqassistant.plugin.plantuml.store {
package de.kontext_e.jqassistant.plugin.plantuml.store.descriptor{}
}
de.kontext_e.jqassistant.plugin.plantuml.scanner ---> de.kontext_e.jqassistant.plugin.plantuml.store
-----
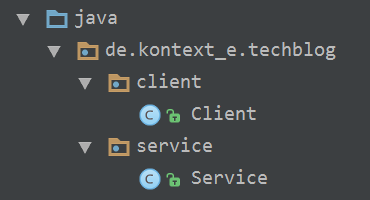
It gets rendered into a UML Package Diagram:
 .
.
As you noticed, the example is from the jQAssistant PlantUML plugin itself. The rendered Asciidoc example Building Block View chapter looks like this:

Add the architecture documentation directory to the scan path
To make jQA also scan the architecture documentation, it must be configured to look into the very same directory.
Maven
Given the architecture documentation resides in ‘doc/architecture’, simply add this folder as a scan target like this:
1
2
3
4
5
6
7
<configuration>
<scanIncludes>
<scanInclude>
<path>doc/architecture</path>
</scanInclude>
</scanIncludes>
</configuration>
Gradle
This is a snippet for scanning a multi-module Gradle project, again with an additional directory to scan for the architecture documentation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
task(jqascan, type: JavaExec) {
main = 'com.buschmais.jqassistant.scm.cli.Main'
classpath = configurations.jqaRt
args 'scan'
args '-p'
args 'jqassistant/jqassistant.properties'
args '-f'
rootProject.subprojects {
args 'java:classpath::'+it.name+'/build/classes/main'
args 'java:classpath::'+it.name+'/build/classes/test'
args it.name+'/build/reports'
args it.name+'/src/main'
args it.name+'/src/test'
}
args 'doc/architecture'
}
After scanning the project we get a graph like this:
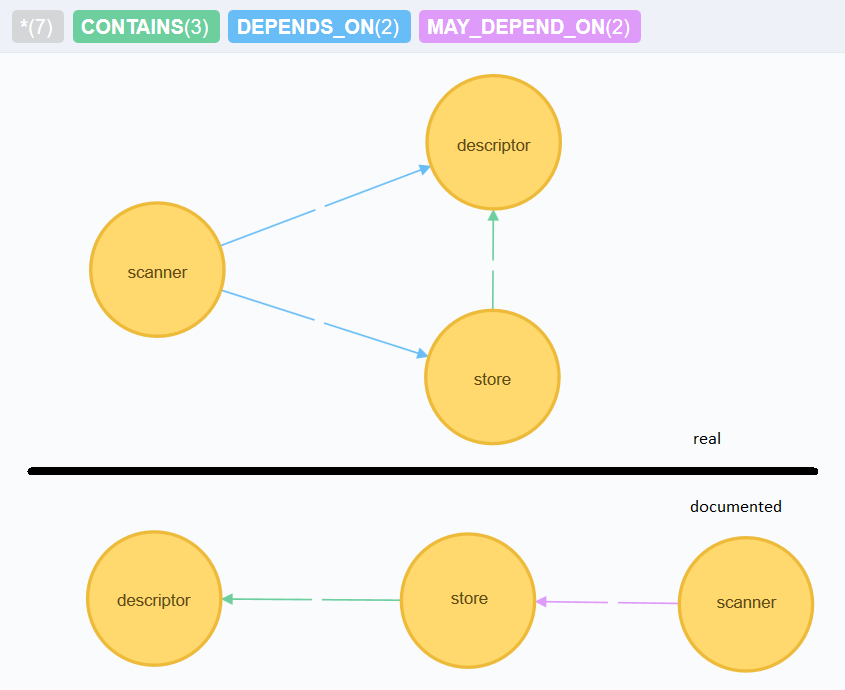
That’s a screenshot of the Neo4j graph browser which I pimped a little bit to make it more expressive. If you try it out exactly at this point, you will notice that in the original scan there is no dependency from scanner to store in the real architecture. This brings us directly to the following section.
jQAssistant Concepts and Constraints
Now as all information is put into one database, expected and actual state can be matched using jQA Concepts and Constraints. In jQAssistant, Concepts and Constraints can be given in XML and Asciidoc. I’ll give the examples for both of them.
XML
In the style of this XML example we add the following snippets.
First, we need a package level as described here:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
<concept id="package:PackageLevel">
<requiresConcept refId="dependency:Package"/>
<description>
Set the level property of a package,
e.g. 1 for de, 2 for de.kontext_e and so on
</description>
<cypher><![CDATA[
MATCH
(p:Java:Package)
WITH
SPLIT(p.fqn,".") AS splitted, p
SET
p.level=SIZE(splitted)
RETURN
splitted, SIZE(splitted);
]]></cypher>
</concept>
This package levels are used to add some transitive package dependencies:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<concept id="dependency:TransitivePackageDependencies">
<requiresConcept refId="package:PackageLevel"/>
<requiresConcept refId="dependency:Package"/>
<description>
Add a DEPENDS_ON relationship to parents of a package P
from other packages up to the same level of the source package.
</description>
<cypher><![CDATA[
MATCH
(p:Java:Package)-[:DEPENDS_ON]->(p2:Java:Package),
(parent:Java:Package)-[:CONTAINS*]->(p2:Java:Package)
WHERE
p.level <= parent.level
CREATE UNIQUE
(p)-[:DEPENDS_ON]->(parent)
RETURN
p.fqn, parent.fqn;
]]></cypher>
</concept>
which come handy to find package dependencies in the wrong direction with this little Constraint:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
<constraint id="dependency:WrongDirection" severity="critical">
<requiresConcept refId="dependency:Package"/>
<requiresConcept refId="dependency:TransitivePackageDependencies"/>
<description>
Finds package dependencies which are in the wrong direction
according to the documentation.
</description>
<cypher><![CDATA[
MATCH
(p1:PlantUml:Package)-[:MAY_DEPEND_ON]->(p2:PlantUml:Package),
(p3:Java:Package)-[:DEPENDS_ON]->(p4:Java:Package)
WHERE
p1.fqn = p4.fqn
AND p2.fqn = p3.fqn
RETURN
p3.fqn + "-->" + p4.fqn AS WrongDirection;
]]></cypher>
</constraint>
Don’t forget to add all of that to the default group:
1
2
3
4
5
6
7
<group id="default">
<includeConcept refId="package:PackageLevel"/>
<includeConcept refId="dependency:TransitivePackageDependencies"/>
<includeConstraint refId="dependency:WrongDirection"
severity="critical"/>
</group>
That’s it.
Asciidoc
And now in the style of the Asciidoc example:
[[default]]
[role=group,includesConstraints="dependency:WrongDirection(critical)"]
- <<package:PackageLevel>>
- <<dependency:TransitivePackageDependencies>>
- <<dependency:WrongDirection>>
[[package:PackageLevel]]
.Set the level property of a package, e.g. 1 for de, 2 for de.kontext_e and so on.
[source,cypher,role=concept,requiresConcepts="dependency:Package"]
----
MATCH
(p:Java:Package)
WITH
SPLIT(p.fqn,".") AS splitted, p
SET
p.level=SIZE(splitted)
RETURN
splitted, SIZE(splitted);
----
[[dependency:TransitivePackageDependencies]]
.Add a DEPENDS_ON relationship to parents of a package P from other packages up to the same level of the source package.
[source,cypher,role=concept,requiresConcepts="package:PackageLevel"]
----
MATCH
(p:Java:Package)-[:DEPENDS_ON]->(p2:Java:Package),
(parent:Java:Package)-[:CONTAINS*]->(p2:Java:Package)
WHERE
p.level <= parent.level
CREATE UNIQUE
(p)-[:DEPENDS_ON]->(parent)
RETURN
p.fqn, parent.fqn;
----
[[dependency:WrongDirection]]
.Finds package dependencies which are in the wrong direction according to the documentation.
[source,cypher,role=constraint,requiresConcepts="dependency:TransitivePackageDependencies",severity=critical]
----
MATCH
(p1:PlantUml:Package)-[:MAY_DEPEND_ON]->(p2:PlantUml:Package),
(p3:Java:Package)-[:DEPENDS_ON]->(p4:Java:Package)
WHERE
p1.fqn = p4.fqn
AND p2.fqn = p3.fqn
RETURN
p3.fqn + "-->" + p4.fqn AS WrongDirection;
----
Running the check
No special things have to be done to run the actual check. It is done in the normal jQAssistant run. So it works on the local machine as well as in the CI process quite easily.
Making HTML (or PDF) out of Asciidoc
One widely used toolchain is Asciidoctor with Asciidoctor Diagram to generate a nice set of HTML documents. There is also Asciidoctor PDF for a direct generation of PDF.
A complete example
These were a lot of snippets. Therefore I created a very basic example that contains all to make it run but nothing else. You can download the sources on GitHub, explore and play around.
If you do a
1
mvn verify
you’ll find four constraint violations.
Stay tune for follow up posts. They explain why the example is called “Uneven Modules” and what can be done for taming the architecture with jQAssistant.
Some closing words
There are of course many other arc42 chapters. Some of them are not suited to be checked automatically, but others may contain also checkable contents like the Design Decisions chapter. For example rules like ‘no java.util.Date anymore’ or ‘use log4j instead of java.util.logging’ are quite easy to enforce.
The Concepts and Constraints above do not cover two things:
- packages that were found but not documented
- packages that were documented but not found
I’m not sure if that is needed and/or useful. Everyone should decide this for the concrete project situation.
So now the CI build creates HTML/PDF architecture documentation and uses the same document to check the defined against the actual architecture. How crazy is this?